Plan, Test, Repeat - your starter pack for Disaster Recovery in the AWS cloud

Filip Ulanowski
Cloud Engineer
19-08-2024 | 9 min read

Cloud - a widely known term used these days and a choice of many organizations to leverage against, compared to on-premise systems. Faster to roll out, easier to manage and overwatch, readily scalable — and that is just the start of the upsides to the IaaS solutions. However, another factor why organizations choose remote systems is the reliability and shifting responsibility for managing several crucial problems — physical networking, data center safety, and power disruptions (brownouts or blackouts). The easily scalable and deployable infrastructure also allows for easy transfers and migrations between systems, increasing availability and reducing times in case of an impact. Let’s look at what AWS offers and how it allows its customers to ensure data and operations are safe — and what you can do to ensure that you are safe in case a disaster happens and recovery is needed.
In this article we:
Describe the division of repsonsibilities
Guide you through the DR preparation phase
Discuss DR testing
Talk about how to best use the AWS toolset
Responsibilities and approaches to preparation
First, assess the scope of what you — as an administrator or user — need to maintain on your end and what the cloud provider — that being AWS’ responsibility. You need to be familiar with the Shared Responsibility Model (SRM) — a descriptive matrix describing who is managing which part of the infrastructure.
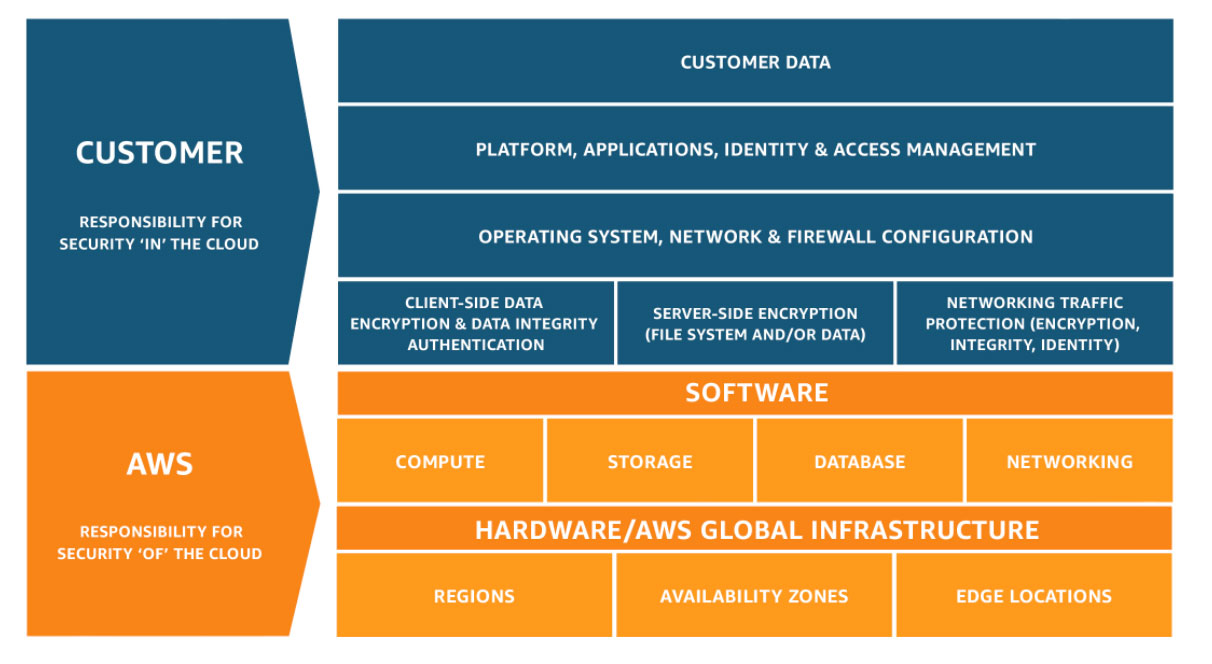
To simplify the SRM — as visible above — Amazon is responsible for security “in” the cloud, while you — are responsible for the security “of” the cloud. Boiling it down — AWS manages the underlying hardware, and connectivity of its backend, and allows access to the aforementioned services. You are accountable for the choices of services you are to provision, their configuration, data stored in there, as well as regional placement — choosing the Regions and their Availability Zones or opting to leverage Edge Locations. That also ties into how you want to approach your strategy in terms of Business Continuity Plan (BCP), and Disaster Recovery (DR) procedures. The BCP also defines what services are present within your system and for your applications — which determines if your infrastructure setup is viable for either one of the solutions for Disaster Recovery scenarios. Once again — AWS does suggest four industry-standard paths that you can follow.
Let’s break them down one by one, and explain their upsides and downsides:
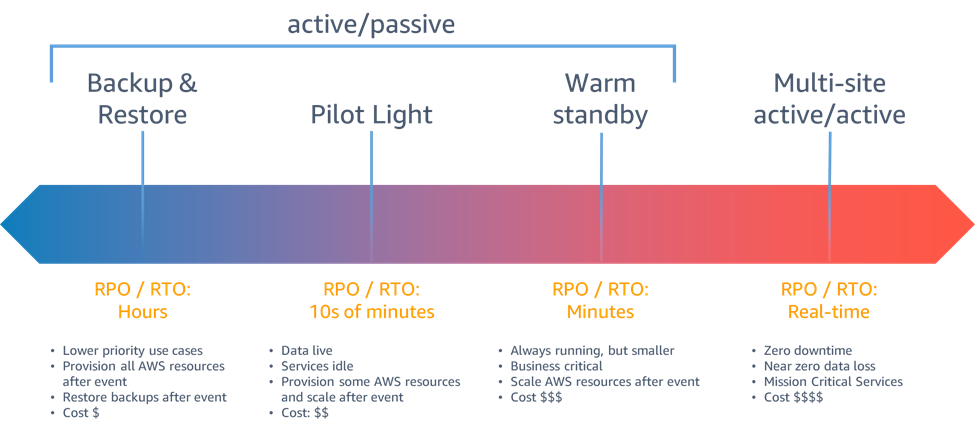
- Backup and Restore — this approach relies on proper backup strategies to do a full environmental redeployment in a secondary deployment zone when the disaster happens. While cheap, as in the cloud, you only have to pay for backups from the primary region — it is the slowest.
- Pilot Light — in this approach, you are keeping a second source of data alive, and deploying some resources, but in cases of EKS deployments or autoscaling groups — you keep them scaled down to zero to ease the switchover when inevitably it all breaks. While faster, it does increase the costs noticeably.
- Warm Standby is a direct upgrade to Pilot Light, where you run the direct copy of the primary environment, just at a higher base capacity than in the secondary scenario. Costs do go up — but the time to recover drops below 10 minutes.
- Multi-site Active/Active — the most expensive, but the fastest way to recover. Thanks to maintaining a 1:1 live copy of the main environment, you need less than a minute to change the routing to shift the traffic onto the second site. It costs the most, but in mission-critical scenarios, it does matter, as the price tag for the solution can be lower than losses caused by the outage.
The path you are willing to take has to be approached carefully — especially when assessing systems’ criticality, needed uptime or RTO/RPO timeframes, and, of course — the costs of maintaining a backup solution. There is no surefire solution that is best for all cases.
Planning for Disaster Recovery
Assuming the appropriate strategy has been chosen for BCP, you can now choose the deployment method to prepare for disasters. Now, there are two paths you can take — Multi-AZ availability, and Multi-Region availability. Let’s analyze them side by side.
Multi-AZ | Multi-Region | |
Costs | Lower, but still increased compared to Single-AZ | Higher, dependent on the BCP plan |
Administration overhead | Lower, due to resource allocation within one region | Potentially bigger from managing assets in multiple regions, and combining them with global services |
Need for architectural changes | Relatively low, based on applications’ capability to handle load from different AZs; some work may be required to ensure high availability | High — a real need exists for creating Cross-Region specific solutions for networking, logging, as well as data and resource replication |
Restore speed in case of service disaster | Relatively quick, service-dependent | Potentially longer, and dependent on architectural setup |
Viability for all applications | Generally possible and viable for all application solutions | Not possible or viable for all applications |
Legal limitations | Non-existent, as data is stored within one operating region | Present — especially for a bigger spread of regions for DRs (for example — choosing NA and EU regions at the same time) |
Time to test or switchover | Relatively fast for all services | Slower for services and dependent on the setup chosen in BCP |
As we can see, there are upsides and downsides to both solutions. Whether you should opt for a Multi-AZ setup or a Multi-Region depends on the need for resource separation, acceptable downtime, cost management, and legal constraints for region-specific regulations. The two primary factors you should consider when designing DR plans and HA architecture are application requirements and regulatory limitations. It may be that because of certain laws — like GDPR for example — your data could not be easily transferred outside the EU regions, and it may require legal work to allow for such operations. Furthermore, you need to remember about issues with running certain applications between multiple regions. In such cases, proper analysis has to be made to consider if you are to still proceed with planning for Multi-Region setup, or for some applications with key data — proceed with Multi-AZ setup. You also need to consider the chances of a disaster impacting both groups. It is more probable for a service to go down within one AZ than in the whole region, but if you require the capability to fully move your services from one region to another, developing an appropriate Cross-Region solution might be the viable pick for you. It may also be that the initial plan you created for Disaster Recovery will not work the first time you run the tests — which is completely valid. Maintaining DR scenarios and honing them is part of a process — a process to reach perfection and rapid response in case a real disaster occurs within the infrastructure. That is also why all plans should be maintained and tested at least biannually.
Running Disaster Recovery tests
Now let’s get to the actual tests. To make it easier, AWS does have an out-of-the-box solution ready, that is the AWS Fault Injection Service (FIS). This tool is built within the AWS Console and injects a surprisingly decent variety of failures within your account. Starting from network shutdowns, injecting network failures, disabling Availability Zones for your Auto Scaling Groups, and forcing AZ failover for your database solutions — all within one place. To put a cherry on top — you have ready packs for simulating AZ and region-wide failures, and all you have to do is target the resources you have deployed within that area. While it does offer some utilities for managing Kubernetes resources, I have found a secondary tool that compliments simulating failures within FIS. I recommend it specifically for Kubernetes DR testing is Chaos Mesh. It expands on the capabilities of FIS while also tying in specific tests forcing platform-specific faults like node restarts and application faults.
It is also worth noting that… AWS FIS supports Chaos Mesh and Litmus testing! By injecting a custom resource into the Kubernetes environment during the FIS experiment setup, you can call the deployed Litmus or Chaos Mesh deployment to start tests based on those tools.
Leveraging the AWS toolset for success
To sum it up — you created your strategy for high availability, ran the tests, and got your results — what now? It is time to improve upon the flaws you have found and gathered in the post-training report. But if you need some more general tips and advice for performing DR tests, as well as improving your infrastructure’s resilience, here are some ideas:
- Enable replication for S3 resources and Elastic Container Registry (ECR) as early as possible for Cross-Region restoration. The reason is that data is only replicated from the moment you enabled the replication — not performing a full copy. While you can bypass it for S3, it may be significantly harder for ECR.
- Take note of secret and parameter store replication — when you enable that for the secondary region, the names are replicated one-to-one, besides the content. If you have IaC within your toolset, be sure to update the region-specific entries like credentials for resources, and keep the previous data for entries that remain the same.
- Remember about global resources like IAM entries or Route53 hosted zones. Especially when leveraging IaC, it may be a good call to work around the codebase to tie existing resources for secondary regions — to ensure that no unnecessary resources are created.
- Refer to your networking documentation and layouts when setting up new VPCs.
- Easy wins to improve your resilience may be things as simple as enabling Multi-AZ modes for your cluster—based resources, like RDS, Elasticsearch, Redis, Kafka, or EC2-based applications.
- Ensure that the backup solution you have is running correctly and that snapshots are available in different AZs or regions. Tools like AWS Backup might be of great help to streamline the process and share it across accounts or regions!
Summary
DRs can be a scary topic — especially if you talk about cross-region exercises and solution development. But once tackled correctly and tested thoroughly, they become less stressful and can improve the reliability of your infrastructure, as well as increase confidence and presence, ensuring that your systems are up and running — no matter what happens. The best piece of advice I can give is to have a proper plan and test it regularly, changing if needed.
Filip Ulanowski
Cloud Engineer



Looking for
cloud expertise?
Get in touch
Are you planning to migrate or looking for more value from your cloud presence?
Schedule an intro call so that we can talk about a tailored solution.

